 [ 打印 ]
[ 打印 ]
DeepSeek(中文名“深度求索”)是一家专注通用人工智能(AGI)的中国科技公司,主攻大模型研发与应用,由量化资管巨头“幻方量化”于2023年7月创立。
DeepSeek也指由DeepSeek公司研发的、类似于ChatGPT、文心一言的智能助手。外界也习惯将该公司开发的一系列大模型产品笼统称为“DeepSeek”。
目前DeepSeek 主要有两条产品线:
V系列:通用对话与内容生成(如 DeepSeek-V3),面向文本生成、客服对话等场景。
R系列:深度推理与逻辑思维(如 DeepSeek-R1),适用于复杂问题求解与科学计算。
截至2025年2月,DeepSeek 目前已发布13个大模型,并全部开源,全球开发者均可利用这些大模型技术开发自己的模型、应用和产品。
模型名称 | 模型类型 | 发布时间 |
DeepSeek Coder | 代码生成模型 | 2023年11月02日 |
DeepSeek LLM | 通用大语言模型 | 2023年11月29日 |
DreamCraft3D | 文生3D模型 | 2023年12月18日 |
DeepSeek MoE | 混合专家模型 | 2024年01月11日 |
DeepSeek Math | 数学推理模型 | 2024年02月05日 |
DeepSeek-VL | 多模态模型 | 2024年03月11日 |
DeepSeek V2 | 混合专家模型 | 2024年05月07日 |
DeepSeek Coder V2 | 代码生成模型 | 2024年06月17日 |
DeepSeek-V2.5 | 融合通用与代码能力模型 | 2024年09月06日 |
DeepSeek-VL2 | 多模态混合专家模型 | 2024年12月13日 |
DeepSeek V3 | 混合专家模型 | 2024年12月26日 |
DeepSeek-R1 | 推理模型 | 2025年01月20日 |
DeepSeek Janus-Pro | 多模态模型 | 2025年01月28日 |
2024年12月,DeepSeek最新V系列模型--DeepSeek-V3首个版本上线,并同步开源。DeepSeek-V3是一个MoE(Mixture-of-Experts)模型,共有671B参数,每个token激活的参数量为37B。为实现高效训练与推理,DeepSeek-V3 延续了 DeepSeek-V2 的 MLA(Multi-head Latent Attention)及 DeepSeek MoE 架构。此外,DeepSeek-V3 首创了无需辅助损失的负载均衡策略,还使用了多 Token 预测训练目标以增强性能。
DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o及Claude-3.5-Sonnet不分伯仲。
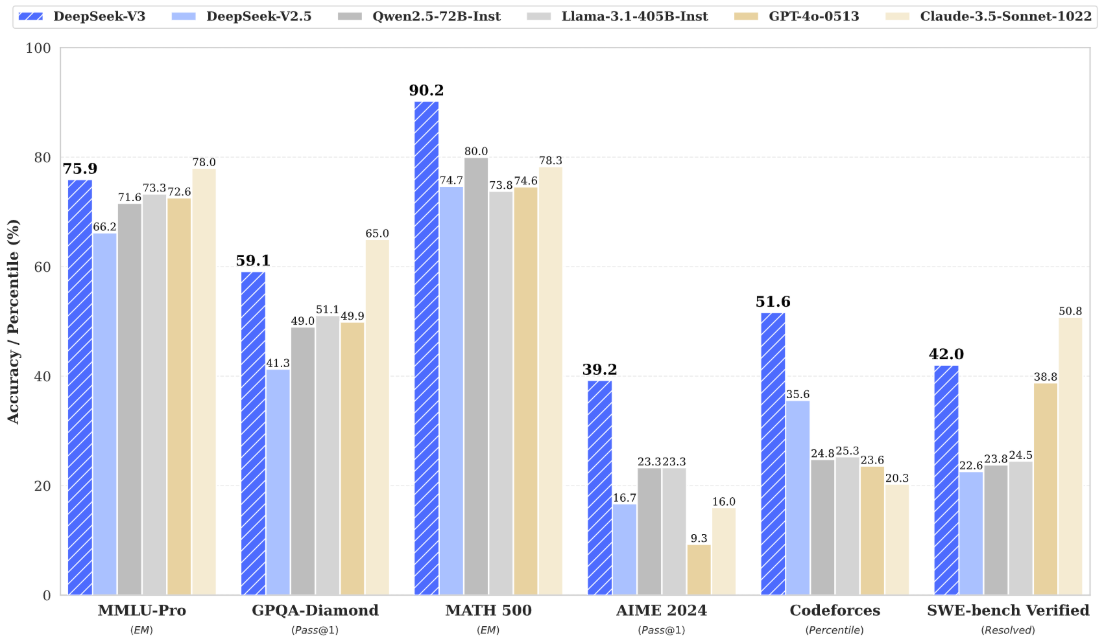
2025年1月,DeepSeek发布了最新R系列模型--DeepSeek-R1(性能对标OpenAI-O1正式版),在数学、编程和逻辑推理方面表现优异。在AIME(美国数学竞赛)等硬核基准测试中,DeepSeek-R1超越了OpenAI-O1模型,受到了全世界的广泛关注。
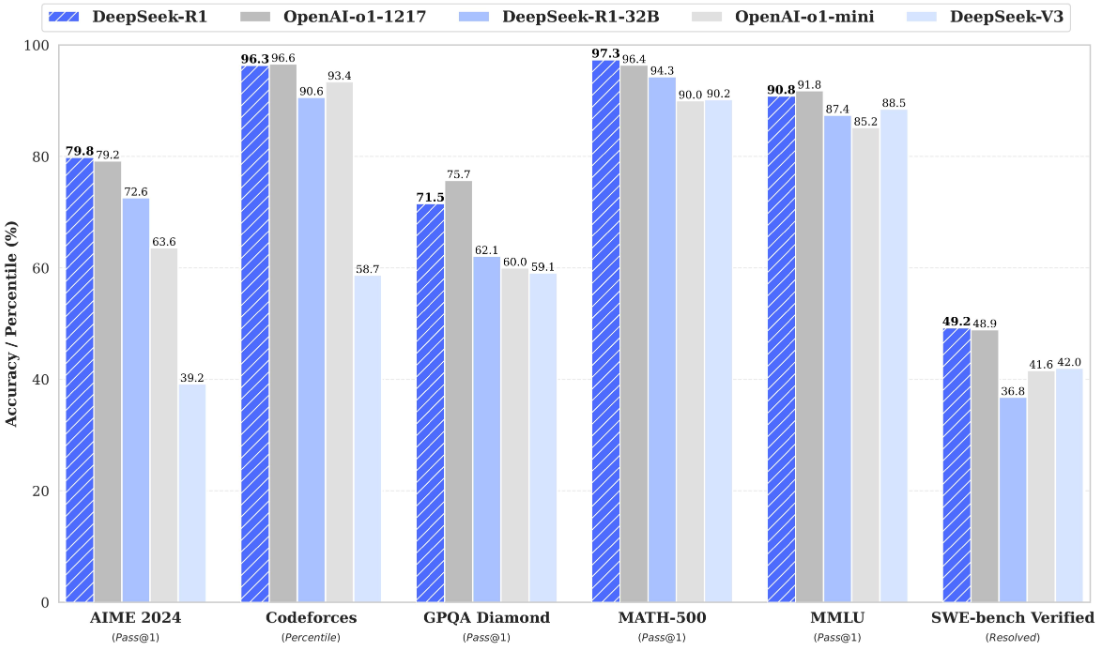
DeepSeek不仅引发了全球新一轮的AI应用热潮,而且对全球的算力资本市场产生重大冲击。究其原因,DeepSeek在训练成本及使用成本、模型训练及优化方式方面均实现了大量工程创新。
DeepSeek发表的原始报告中指出,DeepSeek-V3仅使用了2048块英伟达H800 GPU,耗费了557.6万美元就完成了训练,相比同等规模的模型(如GPT-4o、Llama3.1等),训练成本大幅降低。
DeepSeek的成功展示了”有限算力+算法创新“的发展模式,为中国AI发展提供了宝贵的经验。它证明了在有限算力条件下,通过一系列算法创新同样能够突破算力瓶颈的限制,使开发的大模型获得媲美国际顶尖水平大模型(GPT-4、Claude等)的性能。
DeepSeek出圈,很好地证明了我们的竞争优势:通过有限资源的极致高效利用,实现以少胜多。中国与美国在AI领域的差距正在缩小。
模型在线体验:https://www.deepseek.com
模型下载地址:https://modelscope.cn/models?name=deepseek
DeepSeek-R1 671B满血版具有6710亿参数,这对显存的需求非常高,通常需要多 GPU分布式推理或高性能计算集群来支持。
模型参数 | DeepSeek-R1 671B | ||
模型显存 | 671GB | 335GB | 136GB~226GB |
数据精度 | FP8 | 4-bit量化 | 1.58-2.51-bit量化 |
运行显存最小值(1.3*模型显存) | 872.3GB | 435.5GB | 176GB~239GB |
DeepSeek-R1蒸馏后的版本,如DeepSeek-R1 1.5B/7B/8B版本,可使用Ollama工具在 CPU上部署运行,但一般仅限于单用户,也可以在消费级 GPU(如Nvidia RTX 3090、4090)上部署运行,可支持少量并发用户。对于DeepSeek-R1 70B模型,则至少需要2张24G显存的显卡。如果计算机显存资源不足但内存足够,也可以尝试运行,不过Ollama会使用CPU+GPU混合推理的模式,运行速度相比单纯的GPU模式会下降很多。
设备级别 | 模型版本 | 最低配置要求 |
入门级设备 | DeepSeek-R1 1.5B | 4GB内存 + 核显 |
进阶推荐 | DeepSeek-R1 7B | 8GB内存 + 4GB显存 |
高性能版本 | DeepSeek-R1 32B | 32GB内存 + 12GB显存 |
超性能版本 | DeepSeek-R1 70B | 64GB内存 + 40GB显存 |
CPU:Intel i5-14400F、GPU:Nvidia RTX4060 8G显存、内存:16GB * 2、存储:1TB SSD。
打开Linux终端命令窗口,运行:curl -fsSL https://ollama.com/install.sh | sh。如遇无法下载安装,可通过GitHub下载最新版本压缩包(https://github.com/ollama/ollama/releases)。
通过GitHub下载压缩包完成后,执行命令:sudo tar -zxf ollama-linux-amd64.tgz -C /usr/local,其中/usr/local为解压安装目录(若安装至其它目录下,请注意环境变量设置)。
创建服务配置文件:/etc/systemd/system/ollama.service,直接在终端窗口中执行命令:sudo vi /etc/systemd/system/ollama.service,输入以下内容:
[Unit] Description=Ollama Service After=network-online.target [Service] Environment="OLLAMA_HOST=0.0.0.0:11434" ExecStart=/usr/local/bin/ollama serve User=root Group=root Restart=always RestartSec=3 Environment="OLLAMA_MODELS=/home/ghang/ollama/models" [Install] WantedBy=default.target
保存ollama.service成功后,执行以下命令,使Ollama服务生效。
sudo systemctl daemon-reload sudo systemctl enable ollama sudo systemctl start ollama
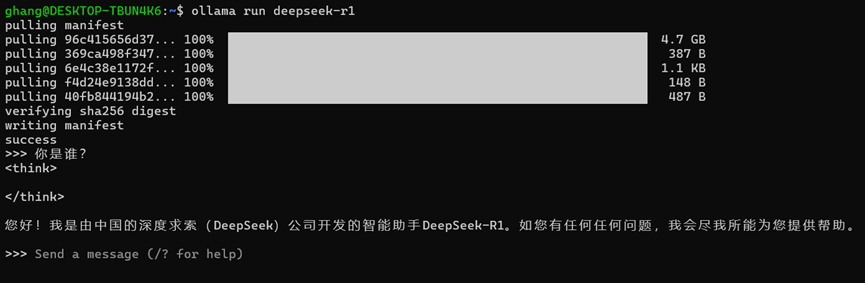
Ollama下载并运行DeepSeek-R1 7B模型。Ollama默认下载Q4_K_M量化版本,模型文件大约4.7GB。
服务器1:CPU:英特尔至强Max 9468 * 2、GPU:HGX H20(96GB) * 8、内存:64GB * 32、存储:3.84T Nvme * 4
服务器2:CPU:英特尔至强Max 9468 * 2、GPU:HGX H20(96GB) * 8、内存:64GB * 32、存储:3.84T Nvme * 4
网络:25Gb以太组网
安装vLLM-docker镜像,在Linux终端中执行命令:sudo docker pull vllm/vllm-openai:latest,拉取镜像。如遇下载失败,可转至国内镜像源,例如:
sudo docker pull docker.1ms.run/vllm/vllm-openai:latest
(1)创建vllm-openai容器,然后进入容器bash窗口,通过Ray指令创建集群。
sudo docker run -itd --gpus all --network host --ipc host --name vllm-openai --rm -v /home/GongHang/models:/workspace/models --entrypoint /bin/bash docker.1ms.run/vllm/vllm-openai:latest
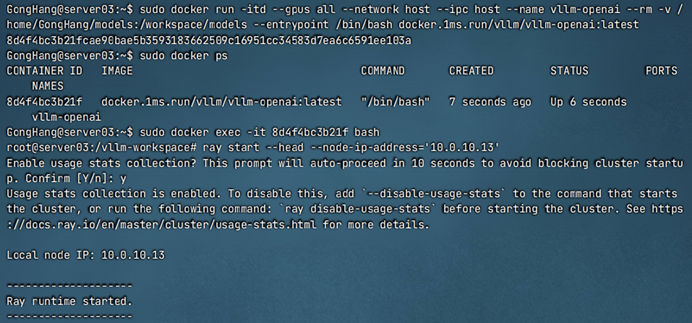
在服务器1中创建head节点:ray start --head --node-ip-address='本机IP'
在服务器2中创建worker节点:ray start --address='head节点IP:6379' --node-ip-address='本机IP'
(2)创建run_cluster.sh脚本文件,使用脚本文件初始化Ray节点(建议使用)。
在服务器1中创建head节点:sudo bash run_cluster.sh 本机IP --head
在服务器2中创建worker节点:sudo bash run_cluster.sh 主节点IP --worker
#!/bin/bash
if [ $# -lt 2 ]; then
echo "Usage: $0 head_node_address --head|--worker [additional_args...]"
exit 1
fi
HEAD_NODE_ADDRESS="$1"
NODE_TYPE="$2"
shift 2
ADDITIONAL_ARGS=("$@")
if [ "${NODE_TYPE}" != "--head" ] && [ "${NODE_TYPE}" != "--worker" ]; then
echo "Error: Node type must be --head or --worker"
exit 1
fi
cleanup() {
if [ -e /var/lib/docker/containers/vllm ]; then
docker stop vllm
docker rm vllm
fi
}
trap cleanup EXIT
RAY_START_CMD="ray start --block"
if [ "${NODE_TYPE}" == "--head" ]; then
RAY_START_CMD+=" --head --port=6379"
else
RAY_START_CMD+=" --address=${HEAD_NODE_ADDRESS}:6379"
fi
# 执行docker命令
docker run -itd \
--entrypoint /bin/bash \
--ipc host \
--network host \
--name vllm \
--gpus all \
--rm \
-v /home/GongHang/models:/workspace/models \
"${ADDITIONAL_ARGS[@]}" \
-e GLOO_SOCKET_IFNAME=bond0 \
-e NCCL_SOCKET_IFNAME=bond0 \
docker.1ms.run/vllm/vllm-openai:latest \
-c "${RAY_START_CMD}"首先,将DeepSeek-R1满血版参数文件移至共享文件夹,或分别拷贝到两台服务器;然后,在任意一台服务器vllm-openai容器bash窗口中,执行以下命令:
vllm server /workspace/models/DeepSeek-R1-671B --host 0.0.0.0 --port 8000 --api-key 01234567890 --gpu-memory-utilization 0.9 --tensor-parallel-size 8 --pipeline-parallel-size 2 --trust-remote-code --served-model-name DeepSeek-R1-671B --disable-log-requests
最后,等待vLLM服务启动。
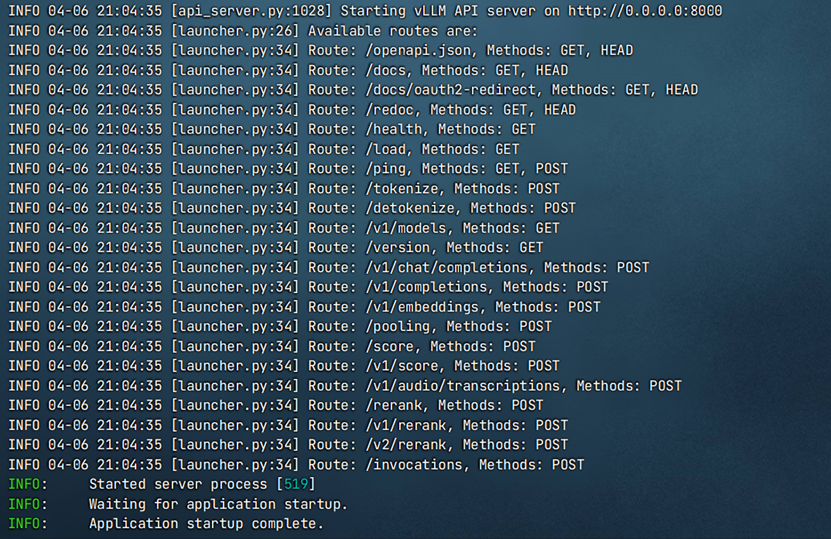
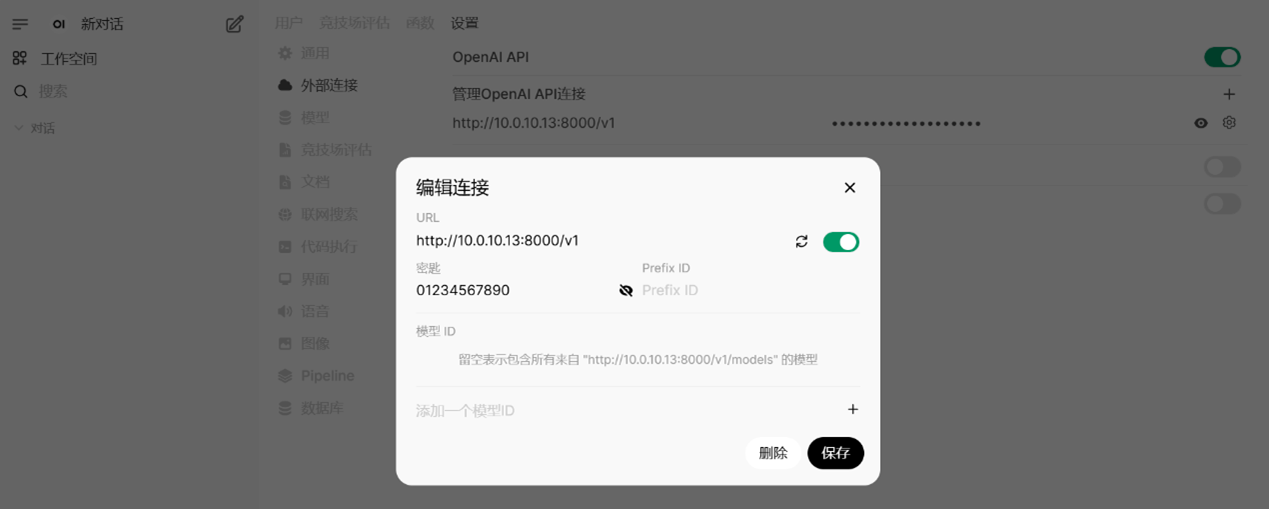
此处使用WebUI(WebUI部署可参考官网教程)验证vLLM服务,依次点击“管理员面板->设置->外部连接->管理OpenAI API连接“,其中URL为vLLM服务地址,密钥为启动vLLM服务过程自定义的api-key。
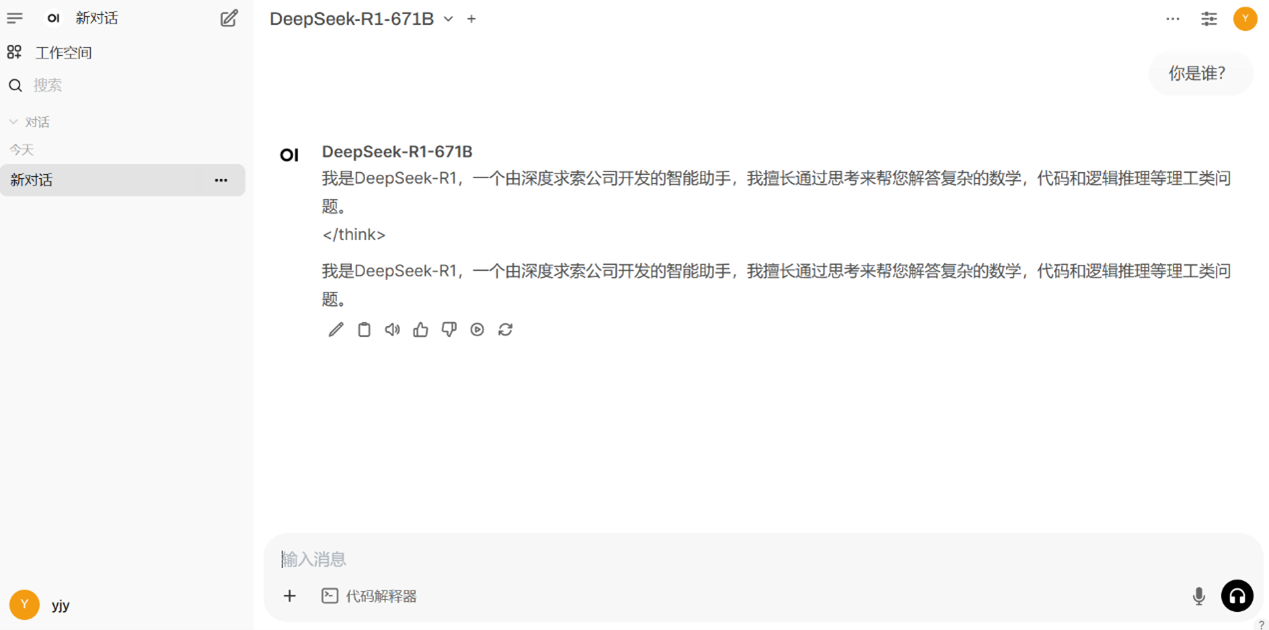
创建聊天窗口,选择DeepSeek-R1-671B模型。
 粤公网安备44020302000244号
粤公网安备44020302000244号

