 [ 打印 ]
[ 打印 ]
(一)基本信息
发布时间:2025年3月6日,由阿里巴巴集团旗下Qwen团队正式发布。
定位:一款轻量化、高效推理的开源大语言模型,对标DeepSeek-R1等大规模模型,目标是通过技术创新实现“小参数、高性能”。
开源生态:采用Apache 2.0开源协议,模型权重已在Hugging Face和ModelScope平台发布,支持Ollama等工具快速部署,适配消费级显卡(如双Nvidia RTX 4090),显存需求较同类模型降低70%。
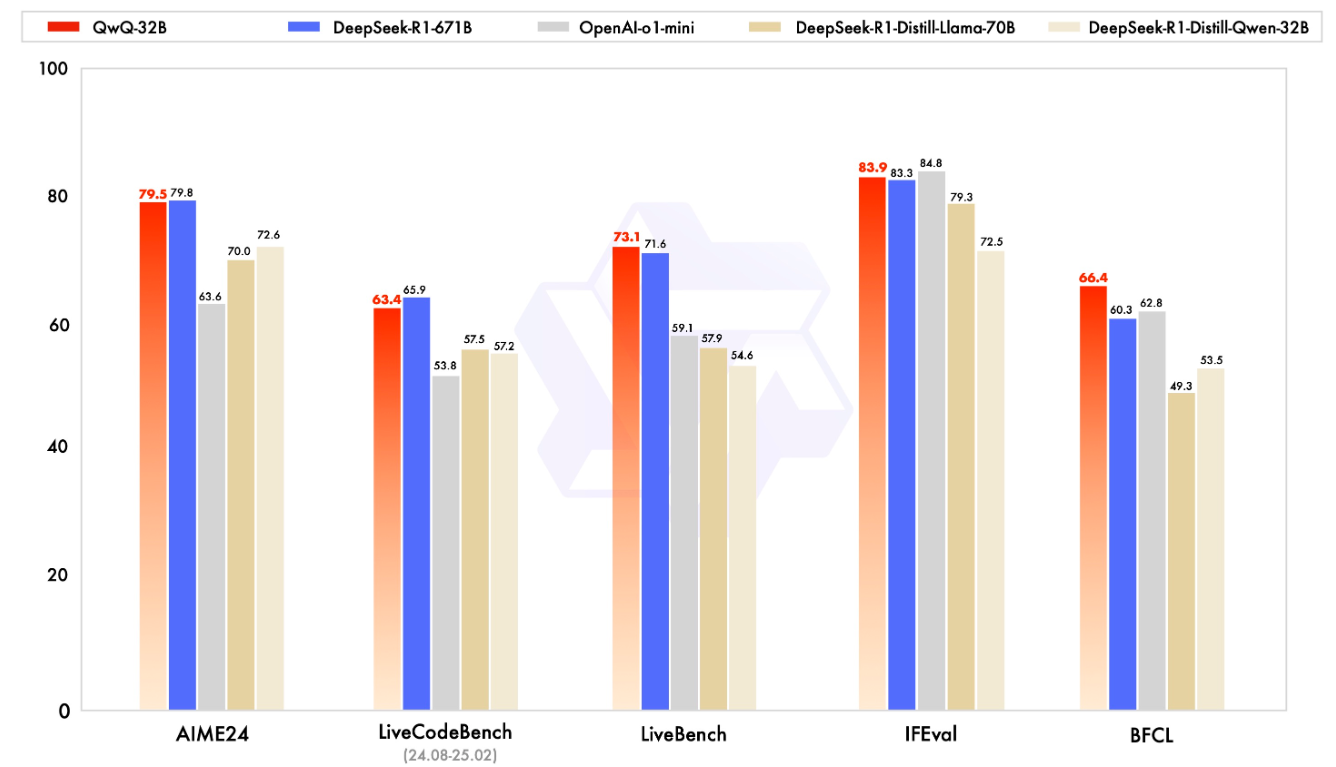
QwQ-32B在一系列基准测试中进行了评估,测试了数学推理、编程能力和通用能力。以下结果展示了QwQ-32B与其他领先模型的性能对比,包括DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、OpenAI-o1-mini以及原始的DeepSeek-R1。
(二)主要功能
强大的推理能力:在数学推理、编程任务和通用能力测试中表现出色,性能媲美更大规模参数量的模型。
智能体(Agent)能力:支持进行批判性思考,根据环境反馈调整推理过程,适用于复杂任务的动态决策。
多领域适应性:基于强化学习训练,模型在数学、编程和通用能力上均有显著提升。
(三)技术原理
强化学习训练:模型针对数学和编程任务进行RL训练。数学任务基于校验答案正确性提供反馈,编程任务基于代码执行结果评估反馈。随后,模型进入通用能力训练阶段,用通用奖励模型和基于规则的验证器进一步提升性能。
预训练基础模型:QwQ-32B基于强大的预训练模型(如Qwen2.5-32B),大规模预训练获得广泛的语言和逻辑能力。强化学习在此基础上进一步优化模型的推理能力,让模型在特定任务上表现更优。
智能体集成:模型集成智能体能力,根据环境反馈动态调整推理策略,实现更复杂的任务处理。
(四)模型体验
在线体验:https://modelscope.cn/studios/Qwen/QwQ-32B-Demo
下载地址:https://modelscope.cn/collections/QwQ-32B-0f1806b8a8514a
二、QwQ-32B本地部署
量化版本:若使用4bit量化(如32b-q4_K_M),24GB显存的显卡(如Nvidia RTX3090、4090)即可支持推理。
原版模型(FP16):需更高显存(约30GB以上),建议使用A100 40GB或H100 80GB等更高配置显卡。
优化特性:QwQ-32B通过强化学习优化,参数量仅为DeepSeek-R1的1/20,显著降低显存占用。
CPU:建议采用多核高性能处理器(如Intel i9或AMD Ryzen 9系列),以支持模型加载与并行计算。
内存:至少64GB DDR4,推荐128GB以上,以处理长上下文窗口(131072 tokens)。
模型文件大小约60-120GB(视量化版本而定),需预留充足存储空间。
(二)Ollama部署QwQ-32B
CPU英特尔至强Max 9468 * 2、GPU HGX H20(96GB) * 8、内存64GB * 32、存储3.84T Nvme * 4。
打开Linux终端命令窗口,运行:curl -fsSL https://ollama.com/install.sh | sh。如遇无法下载安装,可通过GitHub下载最新版本压缩包(https://github.com/ollama/ollama/releases)。
通过GitHub下载压缩包完成后,执行命令:sudo tar -zxf ollama-linux-amd64.tgz -C /usr/local,其中/usr/local为解压安装目录(若安装至其它目录下,请注意环境变量设置)。
创建服务配置文件:/etc/systemd/system/ollama.service,直接在终端窗口中执行命令:sudo vi /etc/systemd/system/ollama.service,输入以下内容:
[Unit] Description=Ollama Service After=network-online.target [Service] Environment="OLLAMA_HOST=0.0.0.0:11434" ExecStart=/usr/local/bin/ollama serve User=root Group=root Restart=always RestartSec=3 Environment="OLLAMA_MODELS=/home/GongHang/ollama/models" [Install] WantedBy=default.target
保存ollama.service成功后,执行以下命令,使Ollama服务生效。
sudo systemctl daemon-reload sudo systemctl enable ollama sudo systemctl start ollama
4. 运行QwQ-32B模型
Ollama下载并运行QwQ-32B模型。Ollama默认下载Q4_K_M量化版本,模型文件大约20GB。
服务器:CPU:英特尔至强Max 9468 * 2、GPU:HGX H20(96GB) * 8、内存:64GB * 32、存储:3.84T Nvme * 4
安装vLLM-docker镜像,在Linux终端中执行命令:sudo docker pull vllm/vllm-openai:latest,拉取镜像。如遇下载失败,可转至国内镜像源,例如:
sudo docker pull docker.1ms.run/vllm/vllm-openai:latest
(1)创建vllm-openai容器
sudo docker run -itd --ipc=host --gpus all --name vllm-openai -p 8000:8000 --rm -v modelscope/models:/workspace/models --entrypoint /bin/bash vllm/vllm-openai:latest
(2)进入vllm-openai终端
sudo docker ps # 获取vllm-openai容器id sudo docker exec -it vllm-openai_id bash # 进入vllm-openai的bash窗口
(3)启动vLLM服务
vllm serve model_tag --host 0.0.0.0 --port 8000 --api-key 1234567890 --gpu-memory-utilization 0.9 --tensor-parallel-size 4 --served-model-name QwQ_32B --disable-log-requests > vllm.log 2>&1 &
(4) 等待vLLM服务启动
此处使用WebUI(WebUI部署可参考官网教程)验证vLLM服务,依次点击“管理员面板->设置->外部连接->管理OpenAI API连接“,其中URL为vLLM服务地址,密钥为启动vLLM服务过程自定义的api-key。![]()
创建聊天窗口,选择QwQ-32B模型。

(1)Ollama:个人开发者快速验证模型效果、低配置硬件(如仅有16GB内存的笔记本电脑);需要快速交互式对话或原型开发。
(2)选择vLLM:企业级API服务、高并发批量推理(如智能客服、文档处理);需要高精度模型输出或定制化参数调整。
对比维度 | Ollama | vLLM |
核心定位 | 轻量级本地化工具,适合个人开发者和小规模实验 | 生产级推理框架,专注高并发、低延迟的企业级场景 |
硬件要求 | 支持CPU和GPU,低显存占用(默认使用量化模型) | 必须依赖Nvidia GPU,显存占用高 |
模型支持 | 内置预训练模型库(支持1700+模型),自动下载量化版本(int4为主) | 需手动下载原始模型文件(如Hugging Face格式),支持更广泛模型 |
部署难度 | 一键安装,开箱即用,无需编程基础 | 需配置Python环境、CUDA驱动,依赖技术经验 |
性能特征 | 单次推理速度块,但并发处理能力弱 | 高吞吐量,支持动态批处理和千级并发请求 |
资源管理 | 灵活调整资源占用,空闲时自动释放显存 | 显存占用固定,需预留资源应对峰值负载 |
附件下载:QwQ-32B介绍与部署.pdf
 粤公网安备44020302000244号
粤公网安备44020302000244号

