 [ 打印 ]
[ 打印 ]
SGlang是一个高性能推理引擎,专为混合专家(MoE)语言模型设计,如DeepSeek-R1。它支持多节点张量并行计算,能够在多台机器上协同工作,从而满足大规模模型的部署需求。此外,SGlang还支持FP8(W8A8)和KV缓存优化,并通过Torch Compile技术进一步提升推理效率。
服务器1:CPU:英特尔至强Max 9468*2、GPU:HGX H20(96GB)*8、内存:64GB*32、存储:3.84T Nvme*4
服务器2:CPU:英特尔至强Max 9468*2、GPU:HGX H20(96GB)*8、内存:64GB*32、存储:3.84T Nvme*4
网络:25Gb以太组网
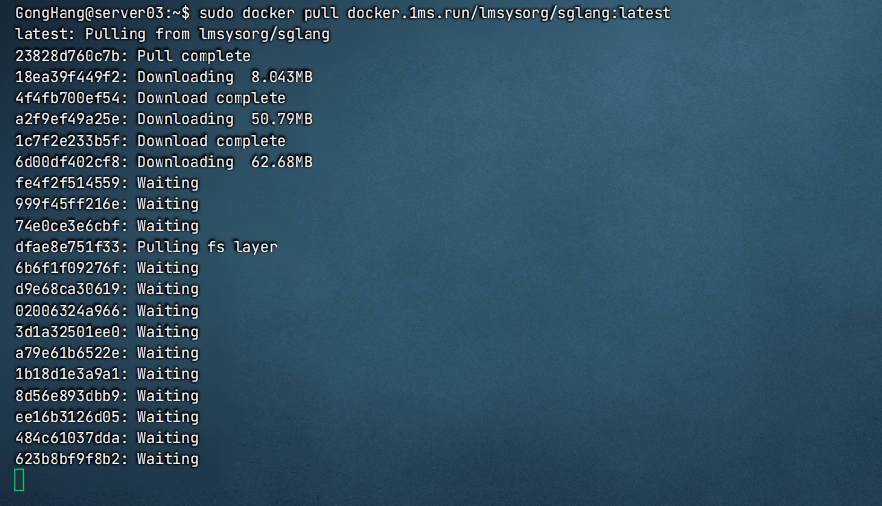
国外镜像源:sudo docker pull lmsysorg/sglang:latest
国内镜像源:sudo docker pull docker.1ms.run/lmsysorg/sglang:latest
1.单台服务器部署Qwen3-235B-A22B。
创建sglang容器
sudo docker run -itd --entrypoint /bin/bash --ipc host --gpus all --name sglang -p 44444:44444 -v /share2/server3/models:/workspace/models --rm docker.1ms.run/lmsysorg/sglang:latest
进入sglang容器终端
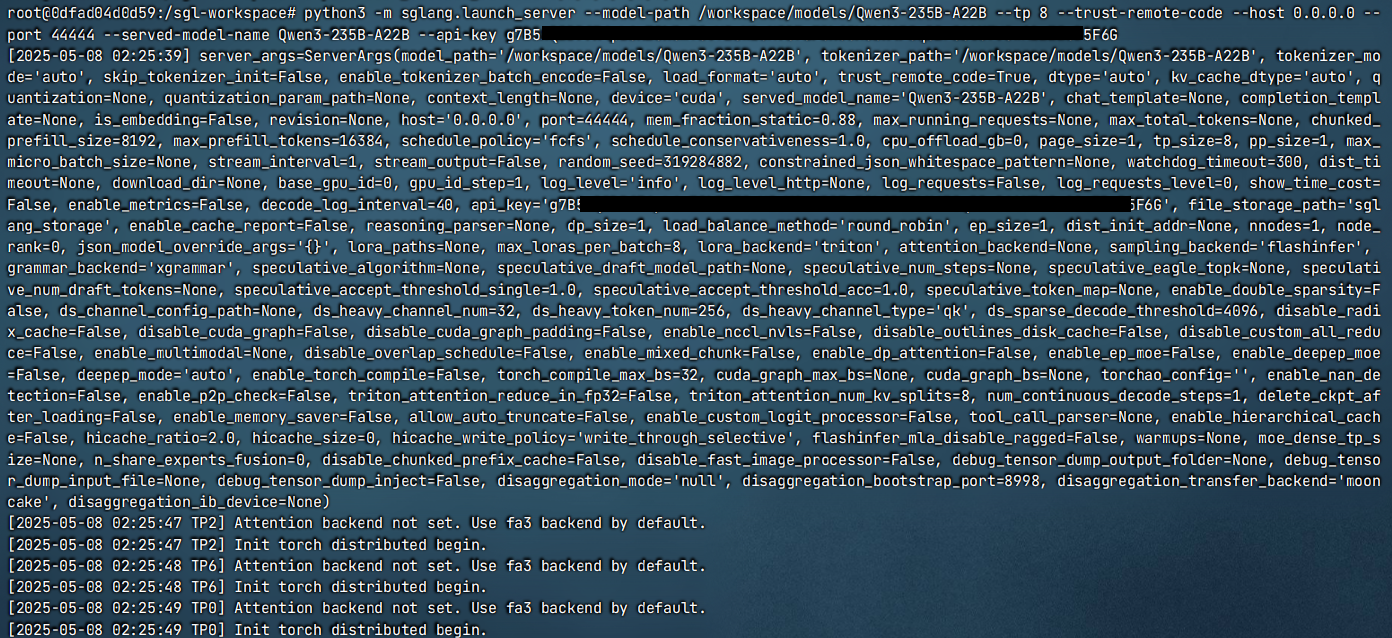
python3 -m sglang.launch_server --model-path /workspace/models/ Qwen3-235B-A22B --tp 8 --trust-remote-code --host 0.0.0.0 --port 44444 --served-model-name Qwen3-235B-A22B --api-key xxxxxxxxxx…xxxxxx
2.两台服务器部署Qwen3-235B-A22B。
分别创建sglang容器(此处“/share2/server3/models”为共享文件夹)
sudo docker run -itd --entrypoint /bin/bash --ipc host --gpus all --name sglang -p 44444:44444 -v /share2/server3/models:/workspace/models --rm docker.1ms.run/lmsysorg/sglang:latest
分别进入sglang容器终端
主节点head:
python3 -m sglang.launch_server --model-path /workspace/models/ Qwen3-235B-A22B --tp 16 --dist-init-addr 10.0.10.11:5000 --nnodes 2 --node-rank 0 --trust-remote-code --host 0.0.0.0 --port 44444 --served-model-name Qwen3-235B-A22B --api-key xxxxxxxxxx…xxxxxx
子节点worker:
python3 -m sglang.launch_server --model-path /workspace/models/ Qwen3-235B-A22B --tp 16 --dist-init-addr 10.0.10.11:5000 --nnodes 2 --node-rank 1 --trust-remote-code
1.在Open-WebUI(WebUI安装过程,请参考官方教程)管理员界面中,设置OpenAI API外部连接。
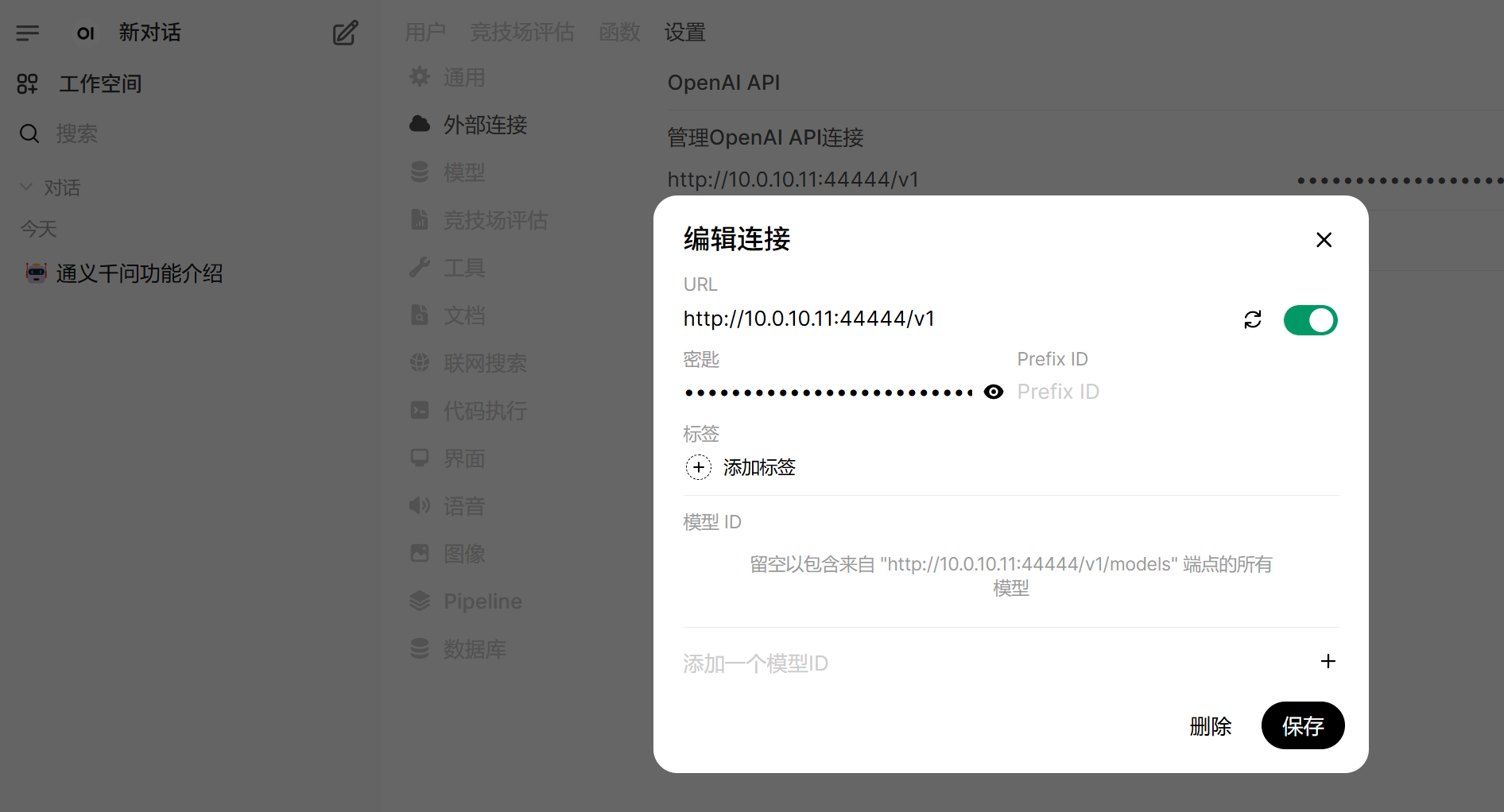
2.创建聊天窗口,选择Qwen3-235B-A22B模型。
附件下载:SGLang部署Qwen3.pdf
 粤公网安备44020302000244号
粤公网安备44020302000244号

