 [ 打印 ]
[ 打印 ]
在人工智能技术迅猛发展的今天,大模型已成为推动产业智能化转型的核心引擎。随着模型参数规模的持续增长,其表现能力不断增强,但与此同时,模型的计算复杂度与计算成本也随之增加。特别是在思维链(Chain-of-Thought, CoT)推理场景中,冗长的推理过程带来了显著的计算开销和响应延迟,直接影响了用户体验,也在一定程度上阻碍了大模型的规模化应用。
近期,哈尔滨工业大学(深圳)、鹏城实验室与韶关市数据产业研究院联合研究团队在大模型推理优化方面取得两项关键进展:一是在思维链压缩方面,利用多轮自适应压缩技术,实现了推理效率提升;二是在思维链蒸馏方面,通过自引导推理依据选择机制,提高了知识迁移效能。相关成果论文已被2025年EMNLP会议(CCF-B类会议、CAAI/清华-A类会议)录用并正式发表,为高效、低成本的行业大模型应用开发提供了可行的技术路径。
一、《From Long to Lean: Performance-aware and Adaptive Chain-of-Thought Compression via Multi-round Refinement》
在复杂推理任务中,大语言模型通过思维链技术展现出卓越性能,但其冗长的推理过程导致了较高的推理延迟和计算资源消耗。现有压缩方法多采用静态或全局优化策略,难以针对不同输入实例的推理复杂度进行动态调整。研究团队基于“Token弹性”现象(当设置过小的Token预算时,模型输出长度反而会增加),提出了一种多轮自适应思维链压缩框架(Multiround Adaptive Chain-of-Thought Compression, MACC),通过多轮渐进式压缩策略,动态确定每个输入的最佳压缩深度。
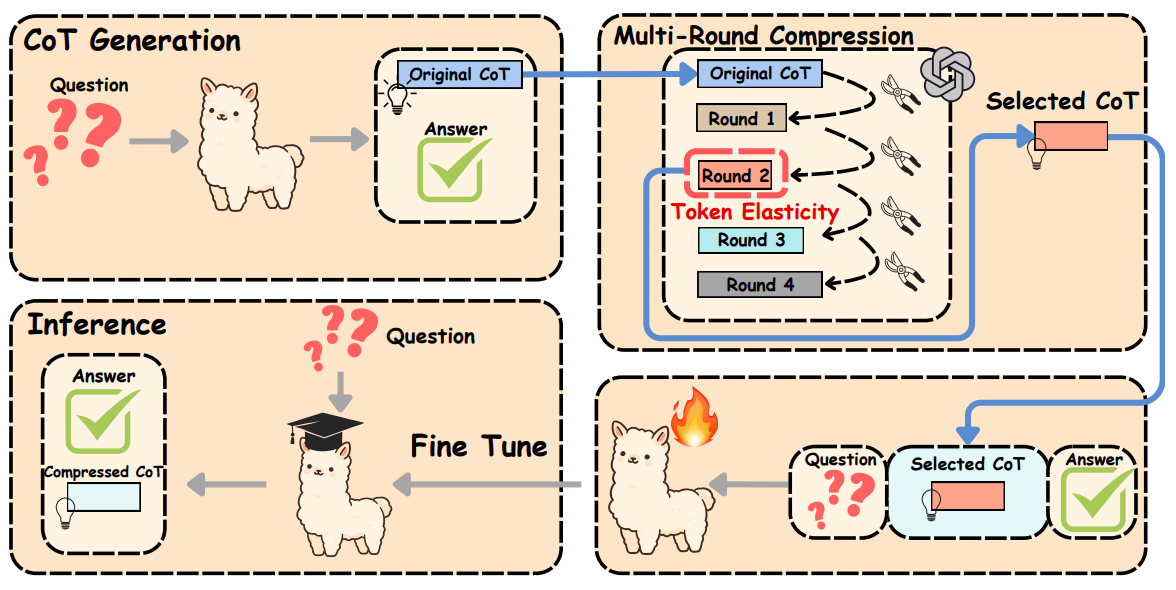 图1 MACC框架
图1 MACC框架
MACC包含了三个核心组件:思维链生成、多轮渐进压缩和多任务微调。
1、在思维链生成阶段:对于每个输入样本,目标模型在标准推理提示下(如:Let’s think step by step)生成完整且未经压缩的思维链,作为后续压缩阶段的原始推理路径。
2、在多轮渐进压缩阶段:引入一个高性能压缩模型,对原始思维链进行多轮迭代精炼。每轮仅移除少量冗余信息或非关键推理步骤,在保留语义完整性与逻辑正确性的前提下,逐步缩短推理长度。该过程巧妙利用了“Token弹性”现象,即当压缩过度导致关键信息缺失时,模型可能生成补偿性冗余,反而使输出长度反弹。通过动态监测每轮压缩后的Token数量,在首次出现长度反弹时终止压缩,从而为每个输入自适应地确定最优压缩深度。
3、在多任务微调阶段:将压缩后的思维链与原始思维链混合,并通过引入特殊压缩标记(如:<compress>)统一输入格式,对目标模型进行多任务监督微调,使其在推理时能直接生成紧凑且逻辑完整的推理路径,在显著降低延迟和Token消耗的同时,保持甚至提升准确率。
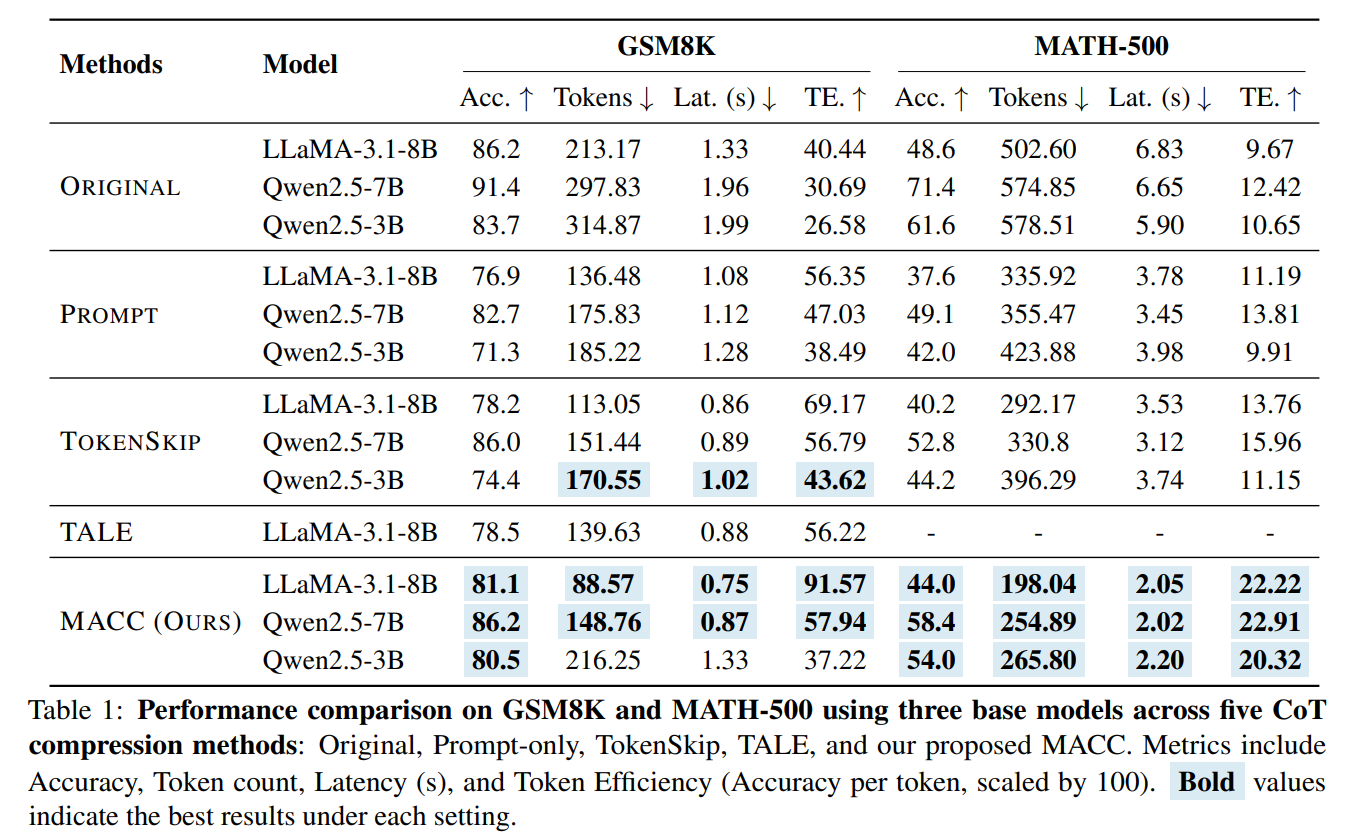
图2 论文实验结果1
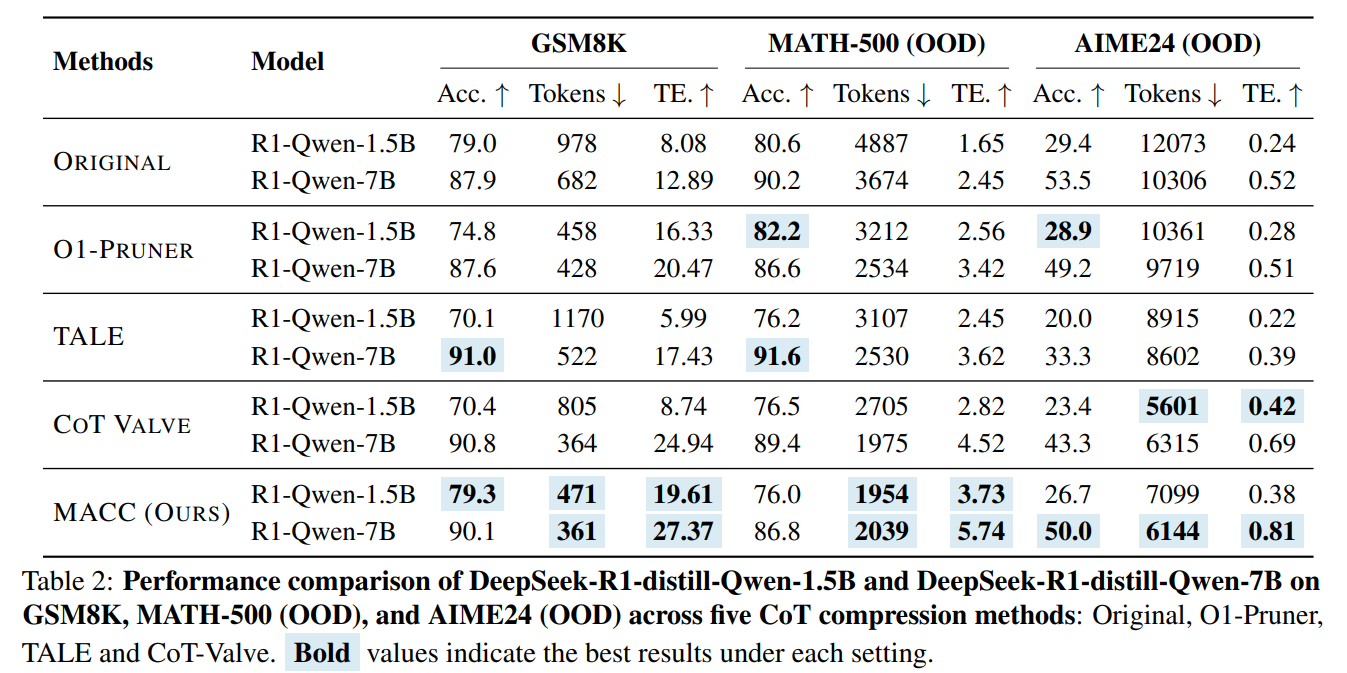 图3 论文实验结果2
图3 论文实验结果2
实验结果表明,MACC在GSM8K、MATH-500和AIME24等多个基准测试上明显优于现有方法,平均准确率提升5.6%,思维链长度平均减少47个Token,推理延迟平均降低40%,在保证性能的同时显著提高了推理效率。
该研究提出MACC框架,结合“Token弹性”与多轮自适应压缩,在大幅缩短思维链的同时提升或保持准确性;并证明微调后的推理性能可通过训练集上的可解释特征(如困惑度和压缩率)可靠预测,为构建高效、可预测的大模型推理系统提供了新范式。论文相关代码将会在https://github.com/Leon221220/MACC发布。
二、《Towards Efficient CoT Distillation: Self-Guided Rationale Selector for Better Performance with Fewer Rationales》
如何将大模型的推理能力高效迁移至小模型,是知识蒸馏领域的一项关键挑战。现有思维链蒸馏方法往往追求数据规模,而忽视了推理依据的质量,容易将带有噪声或错误的中间过程传递给学生模型,从而影响知识迁移的效果。针对该问题,研究团队提出了一种面向模型的推理依据选择蒸馏(Model-Oriented Rationale Selection Distillation, MoRSD)方法,在控制推理依据的准确性、多样性与难度的前提下,以更少样本提升学生模型的蒸馏性能。
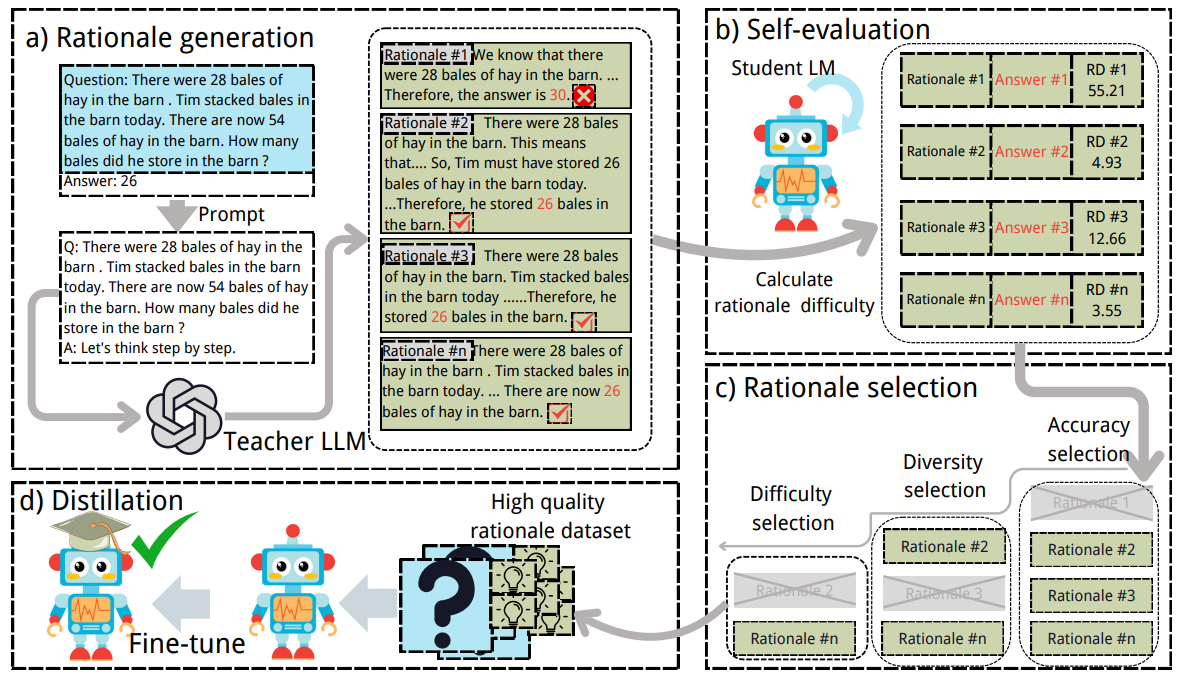
图4 MoRSD框架
MoRSD方法包含四个核心阶段:依据生成、自我评估、依据选择和蒸馏微调。
1、在依据生成阶段:教师模型基于固定提示模板为每个训练样本生成多条候选推理路径,构成完整的初始蒸馏数据集。
2、在自我评估阶段:引入推理依据难度(Rationale Difficulty, RD)指标,学生模型通过计算每条推理路径的推理依据难度,评估其对学生模型的帮助程度,RD值越低表示该推理依据越有利于蒸馏。
3、在依据选择阶段:通过三重过滤机制构建最优蒸馏数据集,首先进行准确性选择,筛选预测结果与标准答案一致的推理路径;然后进行多样性选择,消除相似推理路径以提高数据多样性;最后进行推理依据难度选择,保留对学生模型最有价值的推理路径。
4、在蒸馏微调阶段:学生模型在经上述三重筛选后得到的精简高质推理数据集上进行监督微调,通过端到端训练将教师模型的推理能力高效迁移到学生模型中。
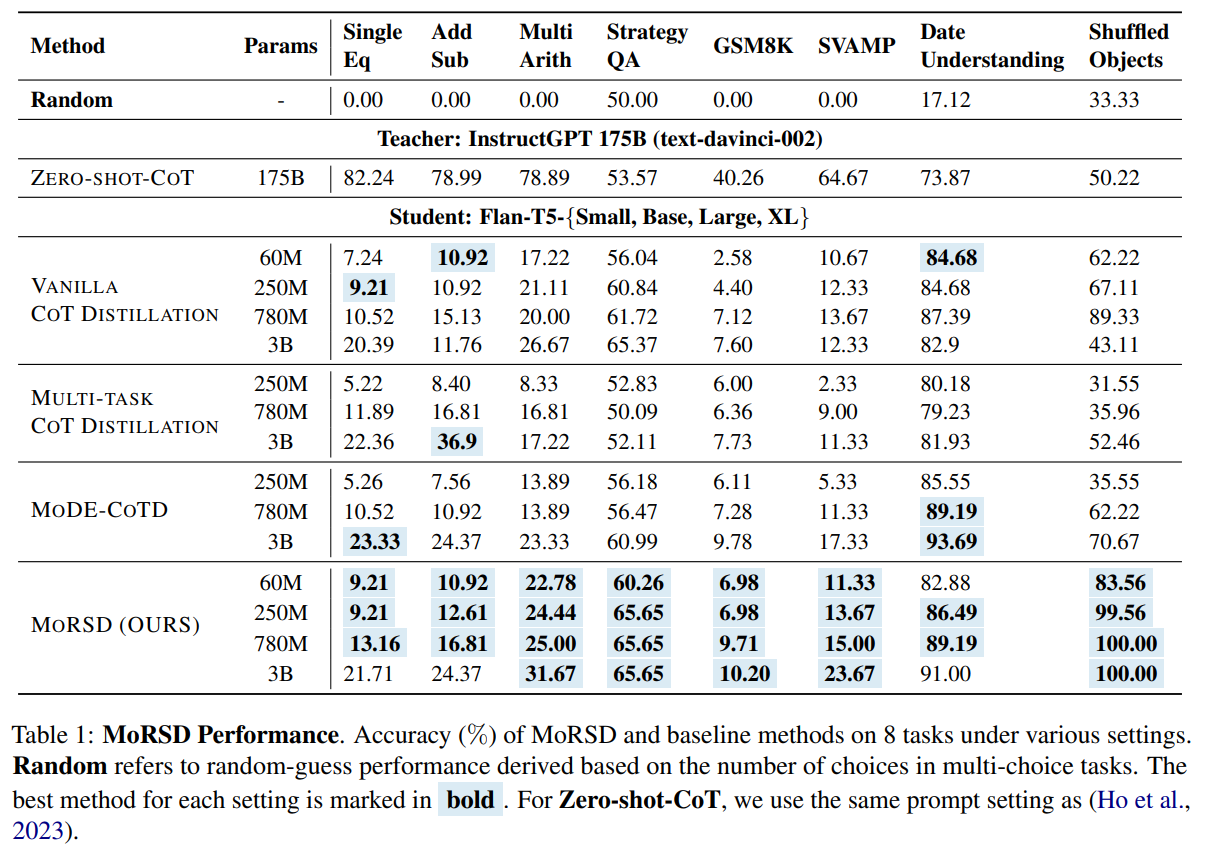
图5 MoRSD实验结果
实验结果表明,MoRSD在涵盖数学推理、常识问答和时空推理的七项基准任务上均优于现有思维链蒸馏方法,平均准确率提升达 4.6%。
该研究验证了“少而精”胜过“多而杂”的思维链蒸馏范式,通过筛选高质量的推理依据,MoRSD不仅提升了学生模型的蒸馏性能,也为构建高效小型推理模型提供了可行的技术路径。论文相关代码将会在https://github.com/Leon221220/MoRSD发布。
 粤公网安备44020302000244号
粤公网安备44020302000244号

