 [ 打印 ]
[ 打印 ]
一、 大模型简介
大模型是指具有庞大的参数规模和复杂程度的机器学习模型。它的参数规模巨大(通常达百亿至万亿级别),并且能通过“大数据+大算力+强算法”的融合实现智能涌现,例如DeepSeek-V3拥有6710亿参数,通过海量数据训练获得文本生成、逻辑推理等能力。它具备泛化性(跨领域知识迁移)、通用性(多任务处理)和涌现性(未预设的新能力)等功能属性,其支持自然语言处理、计算机视觉、多模态交互等复杂任务。
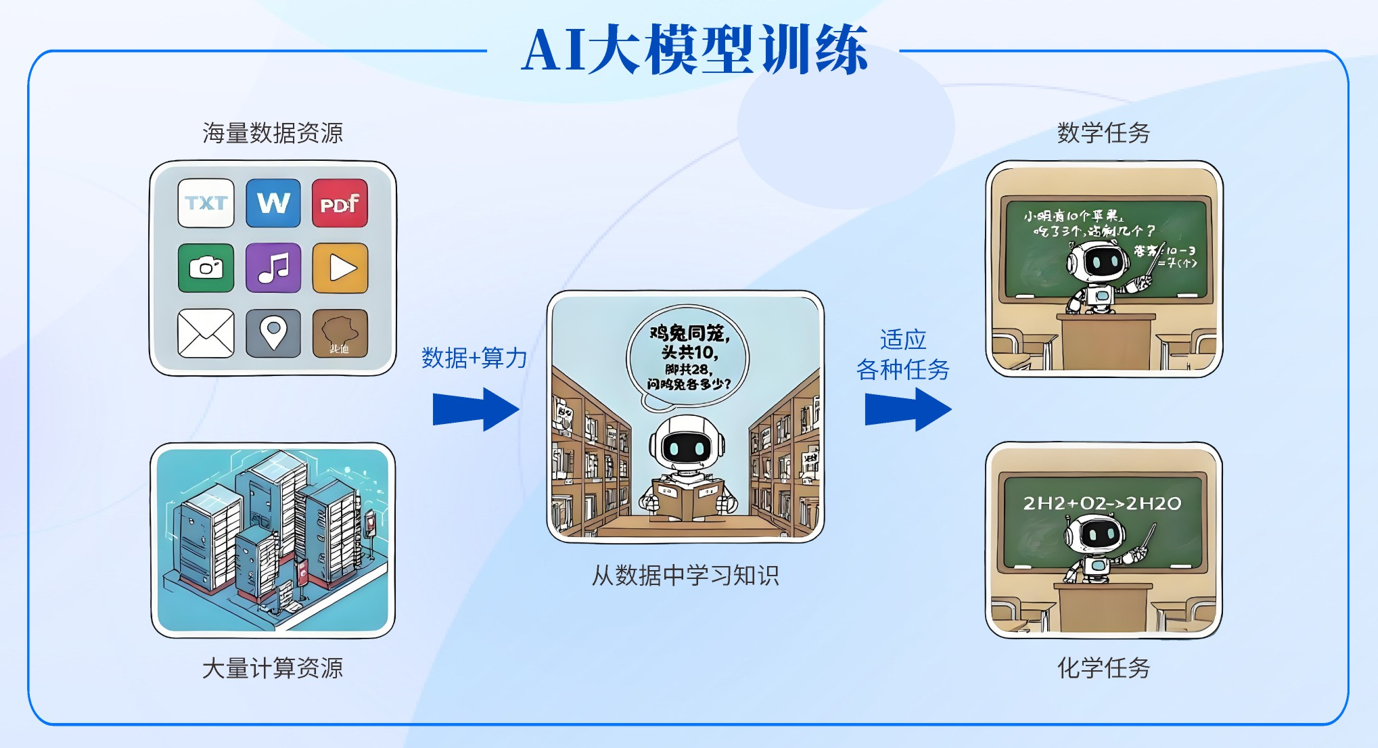 图1 AI大模型训练流程
图1 AI大模型训练流程
根据其应用场景和功能,大模型可分为自然语言处理大模型、计算机视觉大模型、语音识别大模型、多模态大模型、推荐系统大模型、强化学习大模型、生成对抗网络大模型、对话系统大模型等。但是在一般认知中,大模型会被认为是大规模语言模型(Large Language Model)的简称。这是因为自然语言处理(NLP)是大模型技术发展的核心驱动力,早期的AI研究主要集中在文本理解和生成任务上。
此外,语言模型因其强大的通用性,常被作为构建其他领域大模型的基础架构。例如,多模态大模型(如Qwen2.5-VL、GPT-4V)通常以语言模型为核心,通过引入视觉或语音等跨模态信息来拓展其能力边界。相较之下,专注于计算机视觉、推荐系统等领域的大型模型在公众视野中曝光较少,导致语言大模型在舆论中逐渐成为大模型技术的“代表形象”,进一步加深了“大模型即语言模型”的普遍认知。尽管从技术定义上讲,“大模型”实际上涵盖语言、视觉、多模态等多种类型,但当前这一轮技术浪潮的确主要由语言模型引领,使其在大众语境中几乎成了大模型的代名词。
二、 大模型发展历程
20世纪90年代之前,这一时期的人工智能领域还处于初创期,研究人员主要关注的是基于规则的专家和知识表示系统。随着数据资源的不断增加和计算机性能的不断提升,人们开始意识到基于数据驱动的机器学习方法在人工智能领域的巨大潜力。此时的模型主要是基于统计学习的方法,如朴素贝叶斯分类器、决策树和逻辑回归等,但受限于数据规模与质量不足、计算资源匮乏和理论框架不成熟等因素,这些模型性能通常较弱。
2006年,Geoffrey Hinton提出通过逐层无监督预训练的方式来缓解由于梯度消失而导致的深层网络难以训练的问题,为神经网络的有效学习提供了重要的优化途径。此后,深度学习在计算机视觉、语音、自然语言处理等众多领域取得了突破性的研究进展,开启了新一轮深度学习的发展浪潮。
2012年,AlexNet(一种经典的卷积神经网络)在ImageNet(一个用于视觉对象识别软件研究的大型可视化数据库)竞赛中大幅提升图像识别精度,展示了深度学习的巨大潜力。同时期,词向量模型Word2Vec由Tomas Mikolov领导的团队在Google推出,为后来自然语言处理打下基础。
2017年,谷歌研究团队发表具有里程碑意义的论文《Attention is All You Need》,提出了Transformer标准架构。该模型摒弃了传统的循环神经网络(RNN)和卷积网络(CNN)结构,创新性地引入自注意力机制,通过全局并行计算同时捕捉序列内任意位置的关联性,既克服了RNN难以并行化训练的瓶颈,又突破了长距离依赖建模的局限性,奠定了后续大规模预训练模型的技术基石。
2018年Google发布BERT模型,其双向编码器预训练方法推动了自然语言理解技术的飞跃;同年,OpenAI创始人Sam Altman等人推动GPT系列迭代,GPT-1首次验证自回归语言模型潜力。
2019年,OpenAI发布GPT-2,展示了生成式文本模型的潜力;同年,Google的T5模型等也纷纷亮相,Hugging Face公司推出Transformers库,开启了大模型开源生态,极大地降低了大模型的研发门槛。
2020年,OpenAI发布GPT-3,开启了“暴力美学”范式,成为标志性事件,其1750亿参数模型令大规模生成式AI能力突飞猛进,引发全球关注;同年,英伟达发布A100 GPU,单卡算力提升至312TFLOPS,可以支撑千亿参数的训练。
2021年,百度推出文心ERNIE3.0,并探索中文大模型产业落地;同年,谷歌发布Switch Transformer(1.6万亿参数)、微软与OpenAI合作构建万卡级超算集群。
2022年,ChatGPT横空出世,凭借其逼真的自然语言交互与多场景内容生成能力迅速引爆互联网,使大模型技术走进大众视野,推动了从科研到商业应用的跨越。
2023年,大模型多模态能力成为新焦点,各大科技巨头相继推出多模态AI模型,如谷歌的Gemini和Meta的LLaMA等,这些大模型进一步融合文本、图像、视频等信息。同年,OpenAI发布了GPT-4,进一步拓展了模型在复杂任务和多轮对话中的表现。2023年是一个关键的转折点,这一年国内大模型发展呈现爆发式增长态势,百度、腾讯、阿里、华为等老牌科技企业,以及鹏城实验室等科研机构,相继推出文心一言、混元、通义千问、盘古大模型、鹏城·脑海等大模型,百川智能、智谱AI、零一万物、月之暗面等初创企业也加入混战,最终形成了一个“百模大战”局面。
2024年以来,OpenAI 团队相继推出了文生视频模型Sora、多模态推理模型GPT-4o及o1系列,强化模型实时信息处理与复杂推理能力。与此同时,国内大模型产业开始从数量竞争转向质量突破,百度、阿里、腾讯等头部企业加速推进多模态技术融合,在视频生成、实时交互等垂直领域实现技术追赶,推动大模型从基础能力构建向实际应用场景的深度渗透。
进入2025年,全球大模型竞争格局迎来根本性重构。国内深度求索公司(DeepSeek)以突破性的算法优化和完全开源策略,发布DeepSeek-V3和DeepSeek-R1系列模型,一举打破大模型技术长期被OpenAI、Meta、Google等国际巨头垄断的行业格局。DeepSeek的崛起,标志着中国在大模型核心技术领域已从“技术追赶者”转变为“创新引领者”和“规则共建者”,在全球人工智能治理体系中的话语权实现历史性跨越,为构建更加多元、公平、可持续的AI未来提供了强有力的中国方案与技术范式。
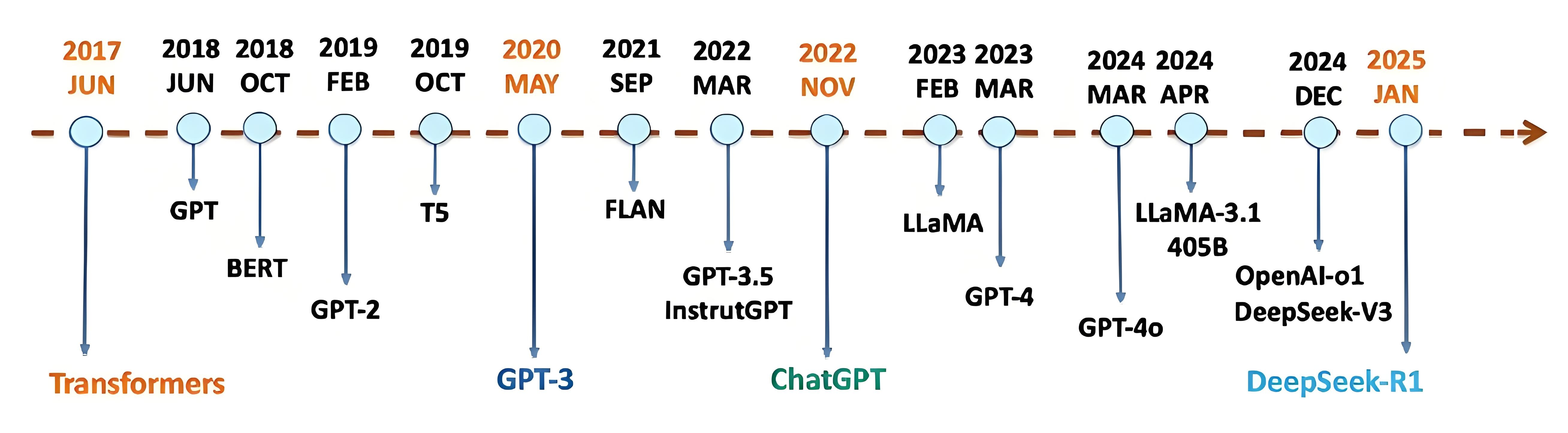
图2 大模型发展简史
 粤公网安备44020302000244号
粤公网安备44020302000244号

